
Why Transformer Blocks Are Built as Residual Updates

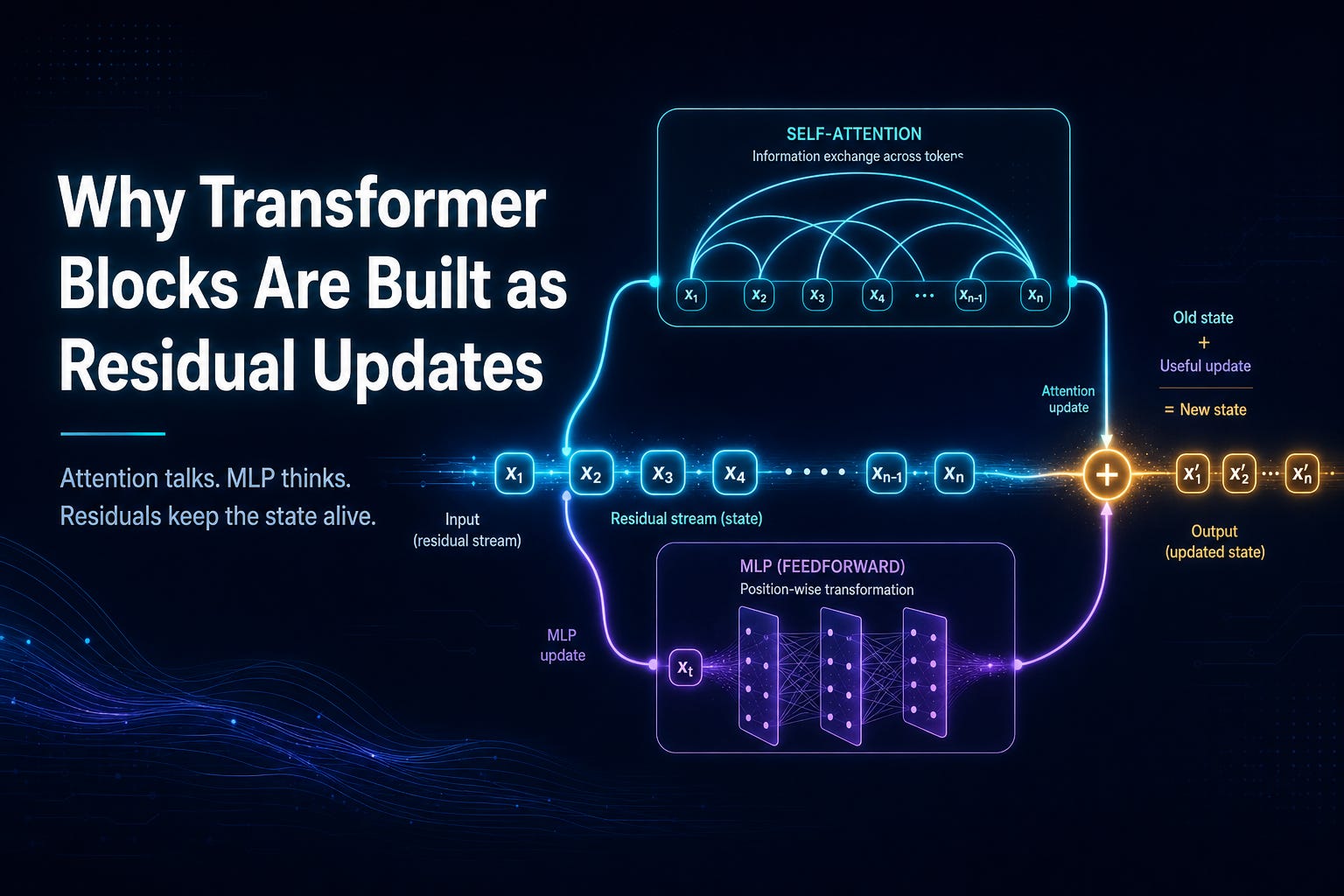
A standard Transformer block often looks like this:
h = h + SelfAttention(LayerNorm(h))
h = h + MLP(LayerNorm(h))
At first glance, this looks almost too simple. Normalize the current representation, run attention, add it back. Normalize again, run an MLP, add it back again.
But this little pattern is doing something important.
A Transformer layer is not trying to replace the current token representation. It is trying to revise it.
That difference matters.
The residual stream is the model’s working memory
Think of h as the current state of every token. Each token already contains some information about itself and, after previous layers, some information about the surrounding context.
The residual connection says:
new_state = old_state + update
This means each layer does not have to rebuild the whole representation from scratch. It only has to compute a useful update.
That is much easier to learn.
Without the residual path, every layer would be responsible for transforming the entire representation into the next useful representation. If the model gets this transformation slightly wrong, information can be lost. If this happens repeatedly across dozens or hundreds of layers, training becomes fragile.
With residual connections, the old state stays alive. The layer can make a small edit:
h = h + something_useful
This is closer to how you might revise a draft. You do not rewrite the whole essay every time you notice a problem. You add a sentence, clarify a phrase, move one idea closer to another. The original text remains, but it gets improved step by step.
That is what a Transformer block is doing to token representations.
LayerNorm keeps the update predictable
The next question is: why apply LayerNorm before attention and MLP?
SelfAttention(LayerNorm(h))
The model’s internal state changes constantly during training. The scale of h can drift from layer to layer and from training step to training step. If attention and MLP receive raw h, they have to deal with a moving target.
LayerNorm gives these modules a cleaner input.
It does not replace the main residual stream. Instead, it creates a normalized version of the current state so the update function can behave more consistently.
This is why modern Transformers often use “pre-norm”:
h = h + block(LayerNorm(h))
The residual stream remains a direct path through the network, while the branch that computes the update gets normalized input.
That direct path is extremely useful for optimization. Gradients can flow through many layers without being repeatedly distorted by every transformation. The model can be deep without becoming impossible to train.
Attention moves information between tokens
Self-attention answers one question:
Which other tokens should this token listen to right now?
Suppose the sentence is:
The animal didn’t cross the street because it was tired.
To understand it, the model needs to connect it back to animal. Self-attention gives each token a way to look at other tokens and pull in relevant information.
So when we write:
h = h + SelfAttention(LayerNorm(h))
we are saying:
Look at the current token states. Let tokens exchange information. Add that exchanged information back into the main representation.
Attention is the communication step.
It lets one token borrow context from another token.
The MLP transforms information inside each token
After attention, each token has more context. But collecting information is not the same as understanding it.
The MLP works token by token. It does not move information across positions. Instead, it transforms each token’s representation internally.
If attention says, “Here is the relevant context,” the MLP says, “Now compute with it.”
For example, once it has attended to animal, the MLP can help encode a more useful feature: this is a pronoun referring to the animal, and tired is probably describing that animal.
So the second half of the block:
h = h + MLP(LayerNorm(h))
means:
Take the updated token representation, process it locally, and add the result back.
Attention mixes information across tokens.
MLP refines information within each token.
The block needs both.
The deeper idea: layers make edits, not replacements
The most important idea is that a Transformer is not a stack of complete rewrites. It is a sequence of incremental edits.
Each block asks:
What context should each token gather from other tokens?
What should each token compute after receiving that context?
What update should be added to the residual stream?
That is why the residual form is so powerful:
h = h + update
It turns deep learning into iterative refinement.
Early layers may capture simple local patterns. Middle layers may build syntactic and semantic relationships. Later layers may form more task-specific features. But each layer is still working with the same basic contract: preserve the current state, then add a useful change.
What people often get wrong
It is tempting to say residual connections exist so the model “doesn’t forget” earlier information.
That is partly true, but it misses the sharper point.
Residual connections make the optimization problem easier. They let the model learn corrections instead of full transformations. If a layer is not useful yet, it can learn an update close to zero. The network can behave almost like a shallower model early in training, then gradually learn to use more layers.
This is one reason deep Transformers are trainable at all.
The architecture is not just about expressiveness. It is about making the learning problem survivable.
A compact mental model
A Transformer block is best understood as:
Read the current state.
Normalize it so the update is stable.
Use attention to exchange information between tokens.
Add that information back.
Normalize again.
Use the MLP to transform each token internally.
Add that transformation back.
Or shorter:
state = state + communication_update
state = state + thinking_update
That is the rhythm of the Transformer.
Attention lets tokens talk.
MLP lets each token think.
Residual connections keep the conversation grounded in what the model already knows.